https://arxiv.org/abs/1912.01603
Dream to Control: Learning Behaviors by Latent Imagination
Learned world models summarize an agent's experience to facilitate learning complex behaviors. While learning world models from high-dimensional sensory inputs is becoming feasible through deep learning, there are many potential ways for deriving behaviors
arxiv.org
Introduction
이 논문에서는 model-based RL 알고리즘, "Dreamer"를 소개하고 있다. Latent space 상에서 task를 수행하는 방식을 사용하며, 이 과정을 여기서는 "Imagination"을 통해 학습한다고 말한다. Contribution은 다음과 같다. (2020 ICLR)
- Learning long-horizon behaviors by latent imagination : Actor-Critic 방식을 적용하여 value를 사용하고, 이로 인해 더 이상 horizon에 제약을 받지 않음. 또한, latent space 상의 imagination 과정을 통해 효율적인 학습이 가능함.
- Empirical performance for visual control : 다른 연구들에서 제안된 여러 representation learning 기법들을 Dreamer와 접목시켜서 그 성능을 비교함. 또한, Dreamer는 이전 model-free 방법들에 비해 data-efficiency, computation time, final performance 측면에서 더 좋은 성능을 보임.
Model-based 알고리즘은 model-free 알고리즘과 비교했을 때, 자체 planing이 가능하기 때문에 반복적으로 같은 경험을 하지 않아도 성능이 잘 나오며, 좀 더 robust하다는 장점이 있다. 하지만, state의 차원이 너무 크면 prediction이 불안정해지고 computation time이 증가하거나 더 많은 memory를 필요로 하는 등의 단점들도 존재한다.
이러한 문제를 해결하고자 이미지와 같은 고차원의 input을 직접 사용하지 않고 이를 latent space 상으로 mapping한 latent state를 사용하는 기법들이 연구되어 왔다. Dreamer 또한 이 방식을 사용하며, 훨씬 더 작은 차원을 갖는, 학습에 용이한 형태를 input으로 활용하기 때문에 더 긴 horizon 동안 prediction을 하거나 multi-modal prediction을 수행할 수 있다는 장점을 갖는다.
Components of Dreamer
기본적으로 imagination을 통해 학습하는 agent들은 다음과 같이 총 3개의 구성 요소를 가지며, Dreamer도 동일한 구조를 갖는다.

- Learn dynamics from experience : 과거 경험들에 대한 dataset으로부터 latent dynamics를 학습하는 과정이다. 과거 observation들과 action을 encode하여 latent state로 표현하고, 이로부터 future reward를 predict한다. 추가적으로, observation reconstruction을 수행하기도 한다.
- Learn behavior in imagination : 예측된 latent trajectory로부터 value와 action model을 학습하는 과정이다.
- Act in the environment : 학습된 action model을 사용하여 현재 state에서의 action prediction을 수행한다 (planning process). 이렇게 수집된 일련의 trajectory는 다시 학습 데이터로 활용될 수 있다.
이 3가지 요소는 agent의 일생동안 계속 반복되며, 순차적 또는 병렬적으로 수행될 수 있다.
(a) Dynamics Learning
첫 번째 구성 요소에 해당하는 dynamics learning과 관련된 내용이다. 즉, imagination을 수행하기 위해 실제 env. (i.e. real world model) 를 approximate한 latent world model를 학습하는 과정이다.
World model은 POMDP로 정의된다.
- Discrete time step : t∈[1;T]
- Continuous vector-valued actions : at∼p(at|o≤t,a≤t) (generated by agent)
- High-dimensional observations and scalar rewards : ot,rt∼p(ot,rt|o<t,a<t) (generated by unknown env.)
- Goal : maxEp(∑Tt=1rt)
Latent dynamics를 학습할 때, 다양한 기법들을 Dreamer에 적용할 수 있으며, 대표적으로 다음의 3가지 방법을 소개하고 있다.
Reward prediction
가장 기본적인 setting으로, 다음의 3가지 model을 사용한다.
- Representation model : p(st|st−1,at−1,ot)
- Transition model : q(st|st−1,at−1)
- Reward model : q(rt|st)
여기서, p는 실제 env.에서 받은 정보를 사용하여 sample을 생성하는 것과 관련된 확률 분포를, q는 latent space 상에서 imagination (i.e. planning)을 수행하는 것과 관련된 확률 분포를 의미한다.
3가지 model 모두 Markovian transition을 기반으로 한다. Representation model은 env.가 주는 observation이 어떤 latent space로 mapping되는지를 encoding한다. Transition model은 latent space 상에서 state와 action이 주어질 때, 다음 latent state로의 mapping을 encoding한다. Reward model은 주어진 state에서의 reward를 예측한다.
하지만, 이러한 setting은 dataset이 유한하고 reward가 sparse한 경우에 대해 한계점을 보인다. 이를 해결하기 위해 reward와 correlate 되어 있는 observation model을 학습하는 방식이 world model의 정확도를 향상시킨다는 연구 결과가 있으며, 두 번째 방법으로 소개하고 있다.
Reconstruction
"PlaNet" (Hafner et al., 2018) 에서는 Fig 3-(a)에서 나타난 바와 같이 image reconstruction (oi→ˆoi) 을 통해 latent dynamics를 학습했다. 이 아이디어를 Dreamer에도 적용할 수 있으며, 아래와 같이 observation model이 추가된다.
- Representation model : pθ(st|st−1,at−1,ot)
- Observation model : qθ(ot|st)
- Transition model : qθ(st|st−1,at−1)
- Reward model : qθ(rt|st)
이러한 4개의 요소들은 joint likelihood를 maximize하는 방향으로 학습이 되는데, ELBO (Evidence of Lower BOund) 또는 VIB (Variational Information Bottleneck)에서 제안한 바와 같이 loss를 설정한다. (요약하자면, likelihood를 바로 maximize 하는게 어려우니까 lower bound를 구하고, 그걸 maximize 하는 아이디어다.)
JREC=Ep[∑t(JtO+JtR+JtD)]+c
where,JtO=lnq(ot|st)JtR=lnq(rt|st)JtD=−βKL(p(st|st−1,at−1,ot)‖q(st|st−1,ot−1))
즉, ELBO와 유사하게 여기서도 observation과 reward에 대한 reconstruction error term, 그리고 KL regularizer term으로 loss가 구성된다. (유도 과정은 논문의 Appendix B 참고!)
각 model의 network 구성은 다음과 같다. 모든 모델들은 하나의 parameter vector θ로 합쳐져서 관리되며, stochastic backpropagation을 통해 update된다.
- Representation model : Recurrent State Space Model (RSSM; Hafner et al., 2018) + CNN
- Observation model : transposed CNN
- Transition model : RSSM
- Reward model : Dense network
Contrastive estimation
마지막 세 번째 방법은 state와 observation 사이 상호 정보를 활용하는 것으로, 아래와 같이 image로부터 state를 predict하는 state model을 사용한다.
- State model : qθ(st|ot)
Loss function은 다음과 같다.
JNCE=Ep[∑t(JtS+JtR+JtD)]
where,JtS=lnq(st|ot)−ln(∑o′q(st|o′))
JS는 Noise Contrastive Estimation (NCE; Gutmann et al., 2010; Oord et al., 2018) 의 아이디어를 가져온 것이며, q(st|ot) 는 현재 image로부터 state를 예측 가능하게 만드는 term이고, 반대로 ln(∑o′q(st|o′)) 는 collapse를 방지하기 위한 diverse를 갖게 만드는 term으로 해석할 수 있다.
통합된 loss JNCE 를 사용하여 θ 를 update하는 과정은 reconstruction 방식과 동일하게 lower bound를 maximize하는 방향으로 optimize를 진행한다.
State model의 network 구성은 다음과 같다.
- State model : CNN
Method Comparison
Dreamer에 reconstruction 방식을 적용했을 때 가장 성능이 좋다고 한다.
(b) Behavior Learning
두 번째 구성 요소에 해당하는 behavior learning via imagination 과 관련된 내용이다. 첫 번째 요소, dynamics learning에서는 world model을 학습하는 latent space를 구하는 것을 목표로 했다. 이렇게 얻은 latent space 상에서 Dreamer는 long-horizon behavior를 학습하게 된다.
World model은 POMDP로 정의되었지만, 학습된 latent space (i.e. imagination env.)는 compact model state st 로 구성된 fully-observed env. 이며, 따라서 다음의 MDP로 정의될 수 있다.
- Discrete time index : τ
- Transition model : sτ∼q(sτ|sτ−1,aτ−1)
- Reward model : rτ∼q(rτ|sτ)
- Policy : aτ∼q(aτ|sτ)
- Goal : maxEq[∑∞τ=tγτ−trτ]
Action and Value models
Imagination env. 상에서 Dreamer는 action과 value를 추정하게 된다. 이 때, actor-critic 방식을 적용하며, finite horizon H 동안의 imagined trajectories를 고려한다.
- Action model : aτ∼qϕ(aτ|sτ)
- Value model : vψ(sτ)≈Eq(⋅|sτ)[∑t+Hτ=tγτ−trτ]
각 model의 network 구성은 다음과 같다. 두 모델은 독립된 parameter를 사용한다.
- Action model : Dense network
- Value model : Dense network
실제로 value를 추정할 때, 위의 식처럼 기댓값을 구하는 과정은 sample들의 averaging으로 대체된다. 하지만, sampling operation은 gradient 계산이 불가능하고, 결국 backpropagation을 통한 model parameter update가 수행되지 못한다.
이러한 문제를 해결하기 위해 "Reparameterizing sampling" 이 제안되었다. tanh-transformed Gaussian 을 사용하여 sampling된 action을 network output에 의해 deterministic하게 결정된 것으로 보는 방식으로, gradient를 계산할 수 있어서 backpropagation이 가능해지게 된다.
aτ=tanh(μϕ(sτ)+σϕ(sτ)ϵ),where,ϵ∼N(0,I)
Value estimation
그러면, imagined trajectory {sτ,aτ,rτ}t+Hτ=t 로부터 value 추정은 어떻게 이루어질까? 여기에도 다음의 3가지 방식이 소개되었다.
- VR(sτ)=Eqθ,qϕ(∑t+Hn=τrn)
- VkN(sτ)=Eqθ,qϕ(∑h−1n=τγn−τrn+γh−τvψ(sh)),h=min(τ+k,t+H)
- Vλ(sτ)=(1−λ)∑H−1n=1λn−1VnN(sτ)+λH−1VHN(sτ)
첫 번째 식은 τ 부터 딱 horizon 까지의 reward만을 고려하고, 그 이후는 무시한다. 두 번째 식은 k step 까지는 discounted reward를 계산하고, 그 이후는 학습된 value model로부터 나온 값을 사용한다. 마지막 식의 경우, 두 번째 식에서 k 를 다양하게 바꾸어가며 exponentially-weighted average를 구한 값을 사용한다.
Dreamer는 마지막 식을 적용하였으며, multi-step return을 사용함으로써 long-horizon task들에 대해 imagination horizon 내에서 robust한 성능을 보여준다.
Learning objective
Action과 value를 update하기 위해, 우선 imagined trajectory를 따라서 모든 state sτ 에 대해 value estimate Vλ(sτ) 를 계산한다.
Action model qϕ(aτ|sτ) 의 objective는 value estimation이 가장 높은 state trajectory를 생성하는 action을 predict 하는 것이다.
maxϕEqθ,qϕ(t+H∑τ=tVλ(sτ))
Value model vψ(sτ) 의 objective는 value를 정확하게 추정하는 것으로, regression task 이다.
minψEqθ,qϕ(t+H∑τ=t12‖vψ(sτ)−Vλ(sτ)‖2)
학습 과정에서 stochastic backpropagation이 사용된다.
Dreamer Algorithm

Experiments
Varying imagination horizons

Performance comparison
Representation (Dynamics) learning

Behavior learning of continous control tasks


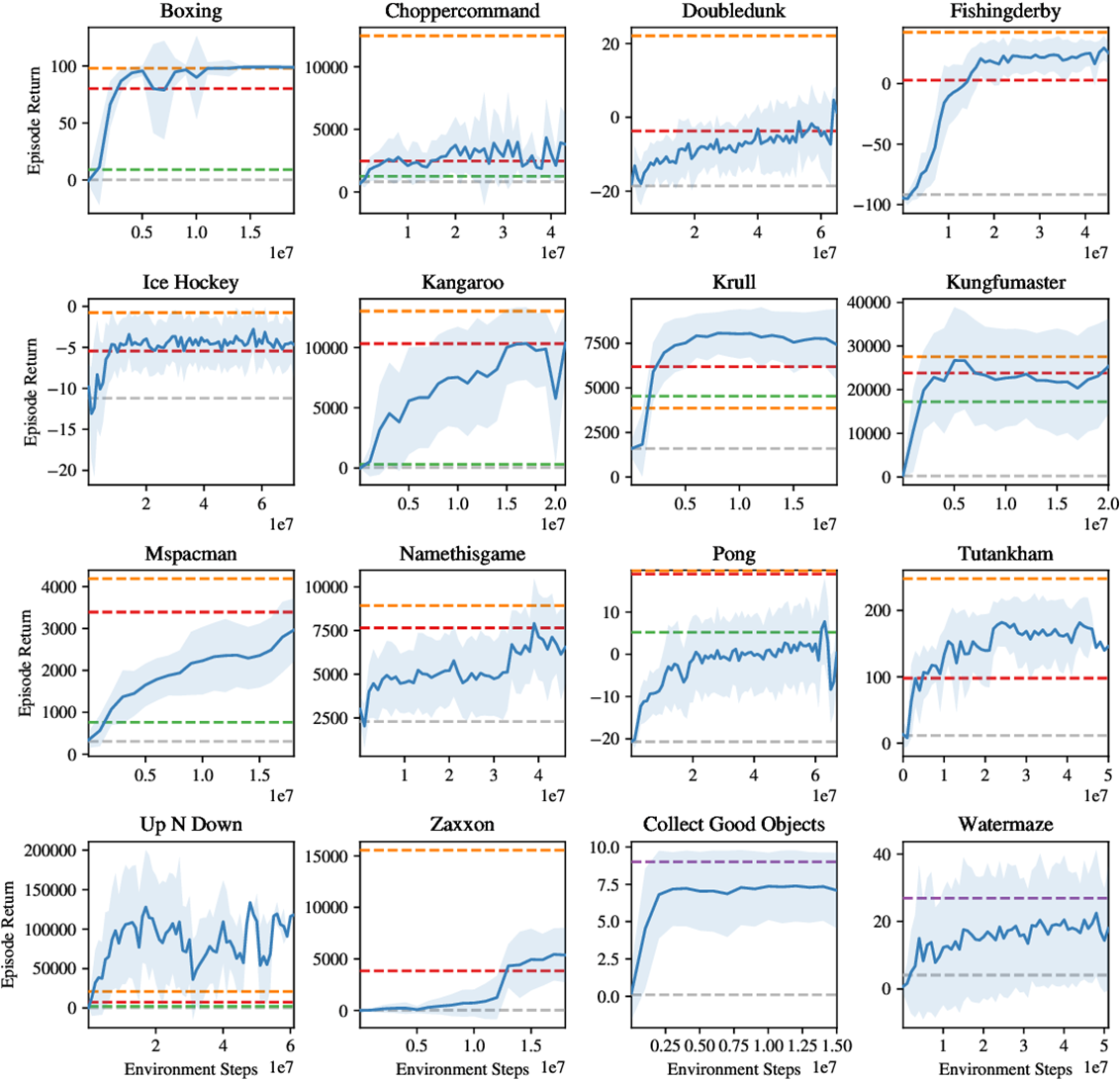
Behavior learning of discrete control tasks
'개념 공부 > Reinforcement learning' 카테고리의 다른 글
| Addressing Function Approximation Error in Actor-Critic Methods (TD3) (0) | 2024.01.31 |
|---|---|
| Asynchronous Methods for Deep Reinforcement Learning (A3C) (0) | 2024.01.30 |
| Soft Actor-Critic (SAC) (0) | 2024.01.27 |


